Unlocking Industry 4.0 with the Converged Four C’s for DataOps

The Undeniable Need for Industrial DataOps
The manufacturing sector is undergoing a dramatic transformation that has been dubbed the fourth industrial revolution. The first industrial revolution involved the adoption of external power generation using windmills and waterwheels, the second industrial revolution included the use of motors in machinery and the electrification of factories, and the third industrial revolution incorporated control automation for the machinery in factories. The fourth wave is a data-driven revolution where data and operations play a significant role in developing and sustaining a competitive, scalable, and innovative facility. For achieving the benefits of Industry 4.0, having a good amount of usable data is important, but what you do with it gives you the edge to stay ahead.
In 2020, during the onset of the pandemic, many traditional industrial sectors like oil and gas, power and utilities, and manufacturing began adopting digital tools to transform, address vulnerabilities and digitize. However, in many of these industries, data was inaccessible and disconnected, and finding usable data was a bigger roadblock than building solutions. To resolve this issue, we need a new hassle-free solution that enables industries to aggregate, standardize and contextualize industrial data from sensors, controls, etc. for business users across the organization. This is exactly what DataOps has to offer.
How do we define DataOps?
The term DataOps can be defined as a framework that addresses issues with data architecture and integration and offers data standards and contextualization for use across the organization. In order to securely deliver reliable, intelligible, and ready-to-use data across the organization, DataOps orchestrates people, processes, and technology in a repeatable and scalable manner. In an industrial setup, DataOps enables collaboration among data stakeholders across the organization.
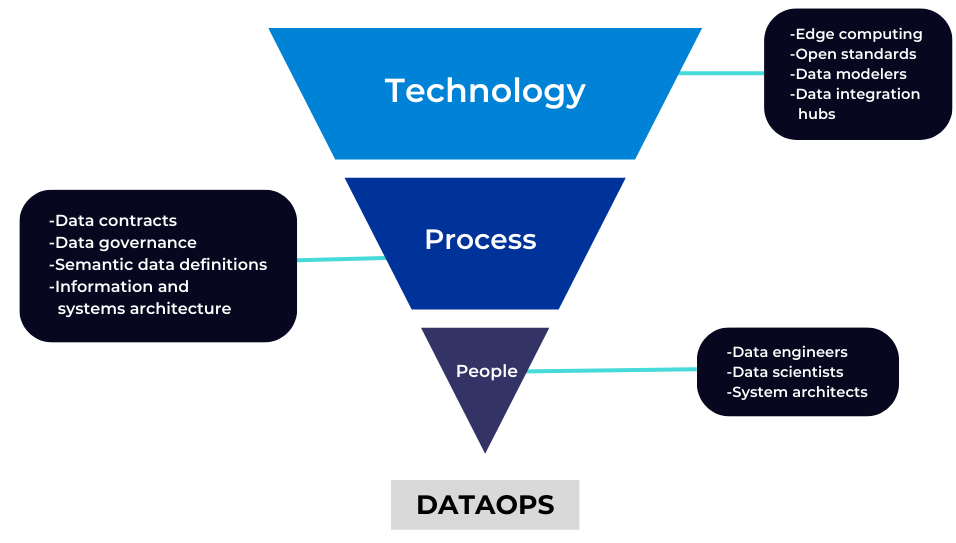
Figure: DataOps involves people, processes and technologies to safely deliver usable data across the organization
How it all started…
Prior to Industry 4.0, industrial data architecture had evolved over the years into a complicated layered approach defined in the Purdue Model or ISA-95. In this model, data flew from sensors to automation controllers to supervisory control and data acquisition (SCADA) or human-machine interfaces (HMI) to manufacturing execution systems (MESs) and finally to enterprise resource planning (ERP). The data volume drastically decreased on moving up the stack. At each point of connection between levels, communication protocols tended to be proprietary and one-of-a-kind rather than reusable ones. Additionally, data integrity was so poor that many businesses updated their MES and ERP systems manually and did not even link them to their manufacturing equipment.
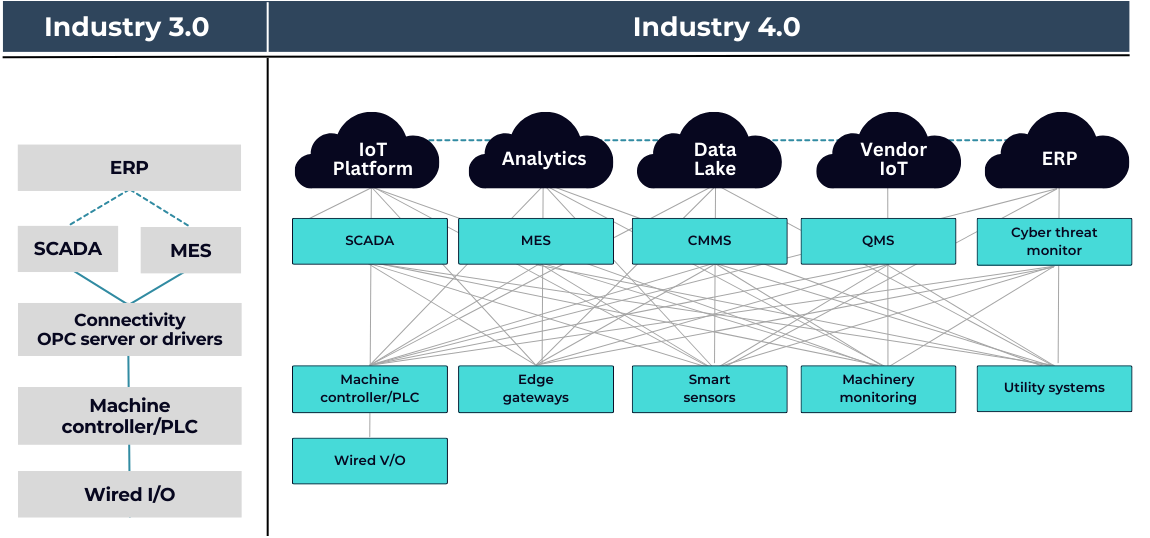
Figure: Overview of Industry 3.0 vs Overview of Industry 4.0
For many years, processing data through multiple layers of systems worked, mostly because the volume of data was manageable. The amount of data being moved up the stack was limited and most of the data used by the system were generated in the previous system. However now, the situation has changed drastically. Pushing excess unused data through systems that do not need it will complicate and slows down data processing capabilities and compromise data security. This is where Industry 4.0 comes to the rescue. Today, data is required close to the equipment, in local data centers, and occasionally in cloud-based systems. A new class of software solutions is emerging to address these issues with data architecture and the need for data contextualization and standardization. These software solutions might hold the key to encouraging businesses to adopt Industry 4.0. When created exclusively for Industrial data, this category is known as Industrial DataOps, or just DataOps.
Essential capabilities of Industrial DataOps
By now, we have established what Industrial DataOps means, but we still have to define the capabilities of DataOps in order to achieve value. An Industrial DataOps platform should have four essential functionalities:
-
Connected Data : This is where data mingles and silos collapse. This makes it possible to conduct in-depth and complicated analysis that would not otherwise be possible. IIoT, cloud, and edge technologies utilize connected data. It is widely accepted that data kinetics enables value maximization, which means that decisions about where to store data should be based on where it can be best accessible and curated rather than on the lowest cost.
-
Curated Data : Curated data refers to the moment the data gets combined into a usable form. As massive amounts of structured and unstructured data continue to get stored in data lakes, unattended data flows to create an environment that is quite similar to a data swamp, making it challenging to identify the relevant data. To ensure the results are as accurate as possible, data engineers simply gather relevant data and clean it up for analysis. They take massive data sets and filter them to the data that is required for a particular scenario. It is important to note that curation is a data engineering activity that includes a lot of sub-activities like data extraction, data cleaning, normalization, and data standardization.
-
Contextualized Data : This indicates that the data has added layers of information and an industry expert is required to give the data more context. In order to derive actionable value from data, organizations must develop the ability to handle both structured and unstructured data, with a focus on contextualizing data depending on specific operational circumstances. The data qualifiers that are included will enhance the meaning of the original data, adding another layer of value beyond simply blending and curating the data that is received. By combining data in novel ways that reveal fresh light on a business or operations issue, contextualization enables the company to be more agile. As with other areas of digital transformation, expanding this maturity across the organization and addressing data quality issues will require new skills and prioritization, understanding business scenarios, and developing automated/ML approaches to help apply context at scale.
-
Cyber-Confidential : This refers to the requirement for cybersecurity to scale along with increasing connection and customization levels of data initiatives. The possibility of mass customization is one of Industry 4.0's most exciting promises. Combining data from numerous sources, including data from customers among many others, is necessary to fulfill that promise. The importance of safeguarding and securing data will increase since businesses will be dependent on incorporating data from customers into production. Customer data must be protected at all costs, but this can add more complexity for specialists in data governance and security and can raise concerns about data privacy. As more and more connected devices are incorporated into our existing manufacturing process, the threat surface increases exponentially. Every product, sensor, and edge device can be a vulnerability that must be safeguarded. This indicates that resource allocation to cybersecurity, data privacy, and compliance issues will need to keep pace with the digital transformation of the manufacturing industry. Increasing vulnerability and threats like advanced malware, worms and advanced persistent threats coupled with GDPR compliance issues will require training the new workforce to specialize in the field of data security.
Conclusion
An agile DataOps platform that captures, organizes, structures, stores and performs analysis of data can go a long way in unlocking the full potential of Industry 4.0. From data sources to consumers, an industrial DataOps platform can handle data at every stage of the production process and convert data into insights that can be used to make business decisions.
To learn more about DataOps you can check out the next set of blogs on our website about how we enable companies to make effective use of their data. At Rawcubes, we help digitize your manufacturing processes through our intelligent data management solution. With us, you’re ready for Industry 4.0. Schedule a demo with us today!