DataBlaze
AI-powered Intelligence Software for Data Discovery and Integration So you can solve bigger problems
Schedule Demo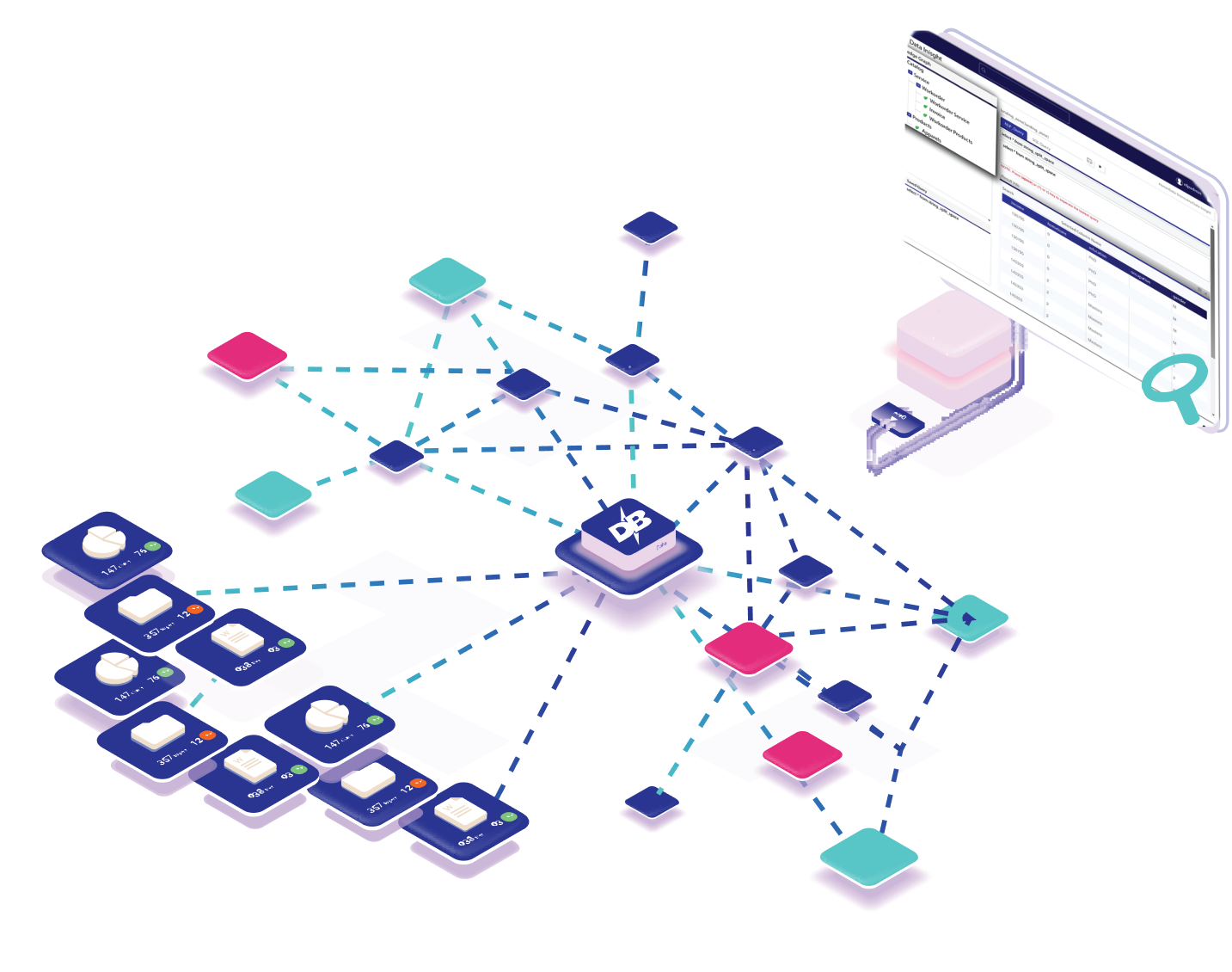
AI-powered Intelligence Software for Data Discovery and Integration So you can solve bigger problems
Schedule Demo
Fueled by our AI-powered data mesh feature, DataBlaze knowledge graph eliminates the need to build complex SQL & joints, While it intelligently identifies hidden relationships from data for unparallel accuracy.
Fyou're adopting next-generation solutions with graph analytics. Our microservices-based architecture embraces a code-free approach, enabling you to quickly build scalable analytical solutions from unlimited data sources.
Unlike traditional data management solutions, DataBlaze goes to work on top of your existing architecture and tech stack. Here are the central pillars powering DataBlaze:
Manual data aggregation from siloed sources belongs in the 20th century. Fast forward to a no-code data integration powerhouse.
DataBlaze automatically brings your data under one roof to save capital and free up your schedule.
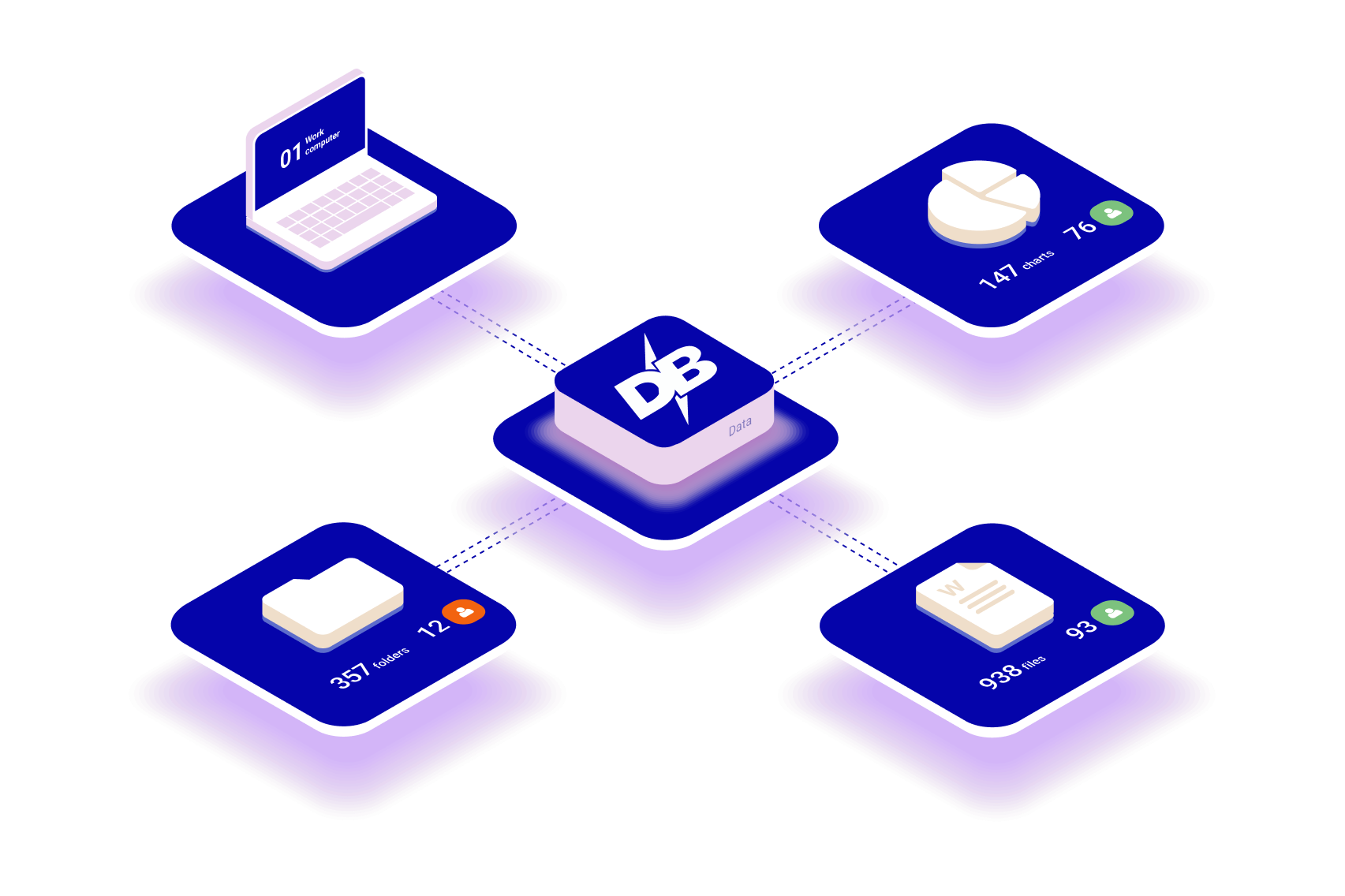

From the customer journey to your day-to-day operations, our knowledge graph enables decision-makers to have access to connected, cross-organizational data without the need for complex code.
As a result, relationships can be frictionless transformed into meaningful insight.
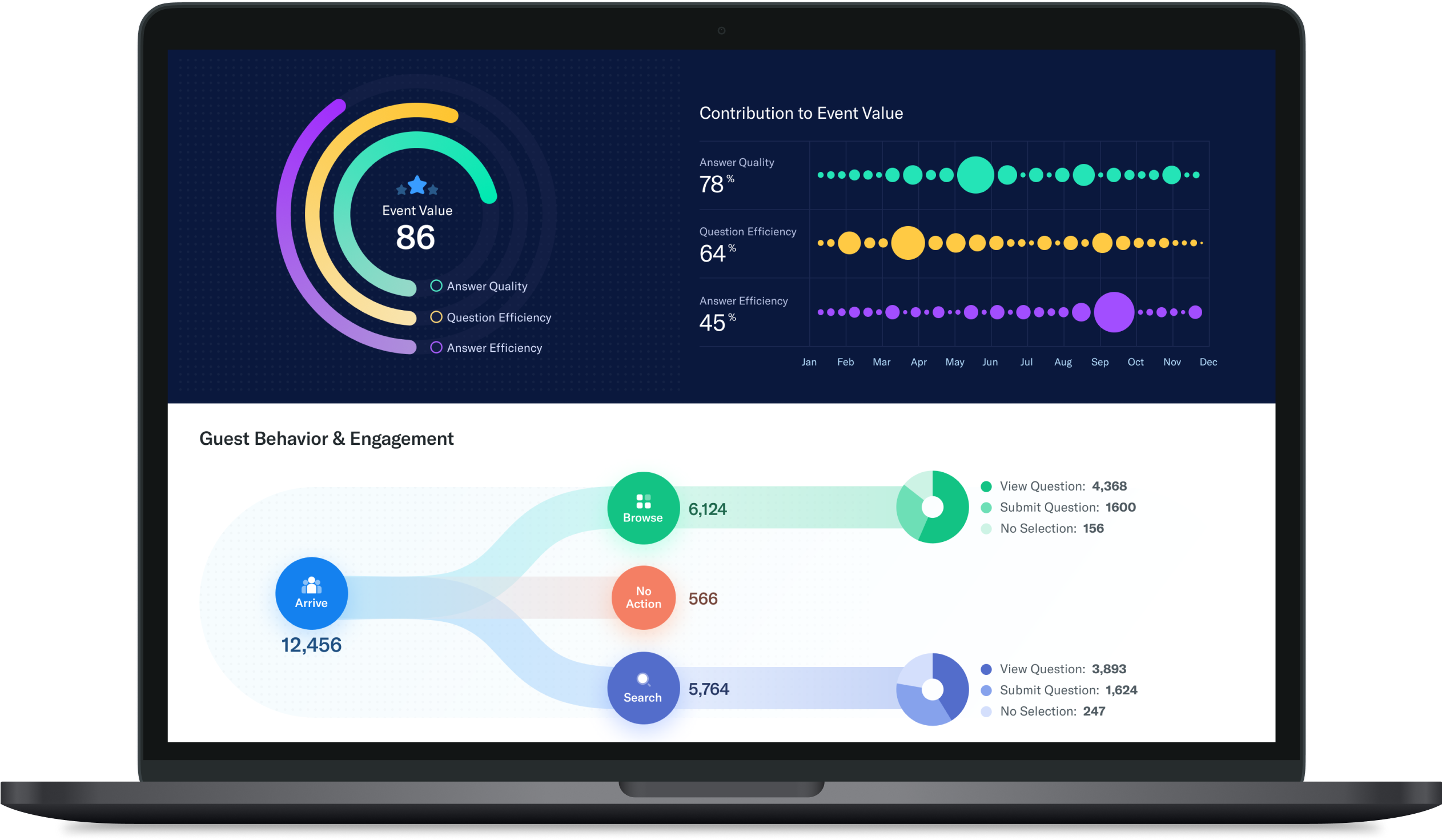
Take the guesswork out of your data preparation efforts. Our solution uses advanced natural language processing (NLP) to unveil the right insight from the right sources at the right time.
Start enacting strategic business plans without depending on subject matter experts. Here's how:

Propel your business forward while streamlining your data efforts. DataBlaze saves countless personnel hours, drives more profitable decisions, and breaks down data siloes. Discover the DataBlaze difference today by booking a complimentary demo.
Schedule Demo