Data Processing Stages Everyone Needs to Know
Leveraging different types of data is a major challenge faced by all companies. Hence, the data must be cleaned before it is utilized. There are various stages involved in data preparation before it can be previewed by a citizen data scientist. Most websites will say the data processing stages are collection, preparation, input, processing, output and storage. However, in this blog, we will discuss data processing stages not only from a Big Data perspective, but also how Rawcubes views data.
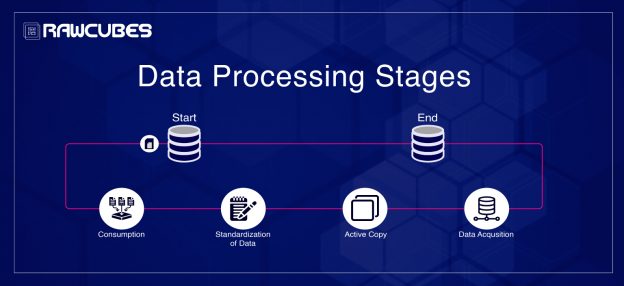
The stages are Data Acquisition, Standardization of Data, Active Copy, and Consumption.
Data Acquisition (Landing Zone):
This is a critical step as it sets the stage for data processing. It involves obtaining raw data, historic data, and incremental data and bringing it to the landing zone. Please keep in mind, this is NOT a data warehouse. Some of the common mistakes at this stage are data reconciliation, mismatched data types and rows, incorrect partitions, not creating a data layout. These mistakes can lead to major issues in subsequent stages. To ensure data is reconciled, it’s always best to check the accuracy of data at each stage. This is why Rawcubes has built-in auditing capabilities as part of audit, balance and control (AB&C) to keep these anomalies in check right at the landing stage.
Standardization of Data (Staging Zone):
Data standardization is a data processing workflow that converts the structure of disparate datasets into a common data format. As part of data preparation, data standardization deals with the transformation of datasets after the data is pulled from source systems and before it’s loaded into the target system. Due to this, data standardization can also be thought of as the transformation rules engine in data exchange operations.
This process enables the data consumer to analyze and use data in a consistent manner. Typically, when data is created and stored in the source system, it’s structured in a particular way which is not known by the data consumer. The way staging is used in big data processing systems varies slightly. Apart from standard extract, transform, and load are also used in a data warehouse. For data lakes, data is already loaded.
At the time of transformation, all special characters can be removed based on your requirements. Data formats are aligned as per industry standard (UTF 8 character set). Data is then exposed by creating metadata definition, such as hive tables, for consumption by data scientists or citizen data scientists. A common mistake at this stage is the absence of data cleansing, resulting in errors during analysis. If we don’t standardize by adding standard data delimiters across all of the data sets, then there is additional overhead for end-users for reprocessing the data for their consumption. A standard metadata definition restricts the user from consistently utilizing all the available data.
Active Copy
Active copy is representation of data as it appears in the source system at a given point of time. Rawcube’s DataBlaze creates an active copy based on the update frequency of the raw data. Also, an active archive is maintained representing the past active copy for the data sets. As per your requirements, older copies can be purged and optimized for storage consumption. Rawcube’s CloudBlaze is a policy-based automation offering active copy creation, purging, as well as movement to cold storage for the purpose of cost optimization.
Consumption (Curation Zone):
Data curation is the extraction of important information from scientific texts, such as research articles, by experts for converting into an electronic format, such as an entry of a biological database.
In the modern era of big data, curation of data has become prominent, particularly for any company processing high volume and complex data.
In the case of DataBlaze and CloudBlaze, curation satisfies customer requirements of clients for supporting business use cases. This includes creation of a feature set for running a predictive model and cleansing of data anomaly before it can be processed by an analytical system.
This is the convention of DataBlaze where Standard Data Model (SDM) is created representing business entity-like policy and claims (insurance industry). The SDM can be used by any company within the same domain. The transformation from SDM to Custom Data Model (CDM) is called data munging (curation or processing of data). The SDM serves as a starting point for data munging to get to a model-specific feature set. The CDM represents the feature set required by a predictive model. This process is essential for downstream consumption by any user looking to gain valuable insights.